- Published on
Unblock Network IO with HTTPX
- Authors

- Name
- Timothy Joseph Baney
I finally got the chance to play around with FastAPI, a highly performant web framework for Python. FastAPI is heavily relient on Starlette, a lightweight ASGI framework. While researching API gateway solutions, we were sandboxing Nginx unit, an application server that supports multiple programming languages. Because of that benefit, I joined a few other developers on my team and built multiple, identical web servers, but using different languages. All web servers were benchmarked under load using siege, vmstat, as well as iostat, and the results were compared.
Stacked against C#, Java, and Node.js, I wasn't expecting Python to perform relatively well, but I was still keen on seeing how performant I could get my FastAPI implementation. A rough summation of my first draft is below:
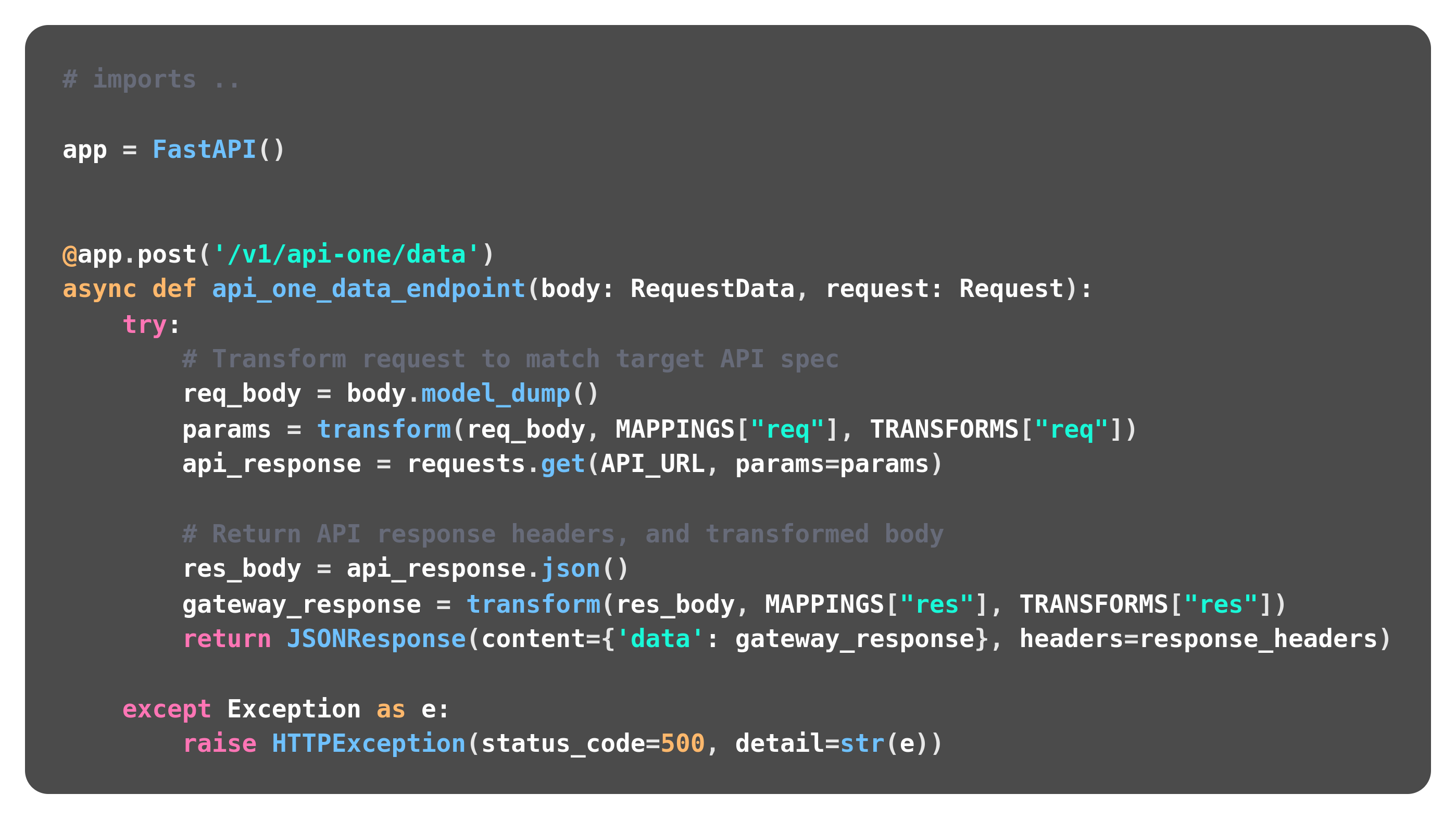
After each draft and benchmarked runs, we came together to share our benchmarks. First results ..
| Python | Java | NodeJS | C# | |
|---|---|---|---|---|
| Failed Requests | 0 | 0 | 0 | 0 |
| Data Transfer (MB) | 145 | 145 | 145 | 145 |
| Elapsed Time | 96.8 | 43.8 | 23 | 19.3 |
| Response Time | 9.3 | 4.1 | 2.2 | 1.7 |
| Txn Rate (Txns/Sec) | 0.4 | 0.9 | 1.7 | 2.1 |
| Throughput (MB/Sec) | 1.5 | 3.4 | 6.8 | 7.5 |
| Concurrency | 3.8 | 3.8 | 3.7 | 3.6 |
| Longest Txn | 15.3 | 5.5 | 5 | 6.7 |
| Shortest Txn | 0.6 | 1.5 | 0.3 | 0.1 |
The divide was between the performance of Python and other languages was surely a code smell. I was confident I had done something wrong setting up my FastAPI web server. Before heading into a second iteration of development, all of us were prompted to go through our source code to ensure all of our implementations were identical (e.g. No middlewares enabled like GZip compression, etc.). The goal was to compare results in as controlled of an environment as we could get. Each set of benchmarks needed to show the same amount of data transferred, and there could be no request failures. The component missing from my web server implementation, that the others had was proper usage of the languages built-in multitasking functionality to mitigate the hit seen from outbound network I/O latency (In this case asyncio event-driven behavior on a single thread). I was using uvicorn, an asynchronous server gateway interface (ASGI), but I wasn't even utilizing it's capabilities. My approach was no different from a Flask server running behind gunicorn.
Before any updates, I decorated my handler with a simple profiler to find any other glaring issues which could be resolved to make the execution of the code faster. Results from a profile of my running web server shows a flat stop when it relays off the incoming request to another internal API. Uvicorn, the async web server gateway that handles requests to FastAPI running on the same process just looks down at it's wristwatch and waits, while 39 other requests are eagerly waiting to be resolved.
3.055 Handle._run asyncio/events.py:78
- 3.055 coro starlette/middleware/base.py:65
[8 frames hidden] starlette, fastapi
3.054 run_endpoint_function fastapi/routing.py:182
- 3.048 live_vol_quotes asgi.py:134
| - 2.745 get requests/api.py:62 <--- THIS GUY
| [34 frames hidden] requests, urllib3, socket, <built-in>...
| 2.036 getaddrinfo <built-in>
| - 0.111 <listcomp> asgi.py:159
| - 0.109 transform asgi.py:13
| - 0.076 [self] asgi.py
| - 0.103 JSONResponse.__init__ starlette/responses.py:188
| [6 frames hidden] starlette, json
| - 0.086 Response.json requests/models.py:944
[4 frames hidden] requests, json
It's crucial to understand the choice of httpx over requests in the context of FastAPI and asynchronous programming. While requests is a popular choice for synchronous HTTP operations, it falls short in async environments. httpx, on the other hand, is tailored for async programming, seamlessly integrating with Python's asyncio event loop. This compatibility allows for efficient handling of non-blocking network requests and better utilization of concurrent connections. In scenarios like ours, where rapid response and high concurrency are key, adopting httpx is not just a matter of preference but a necessity for optimizing performance
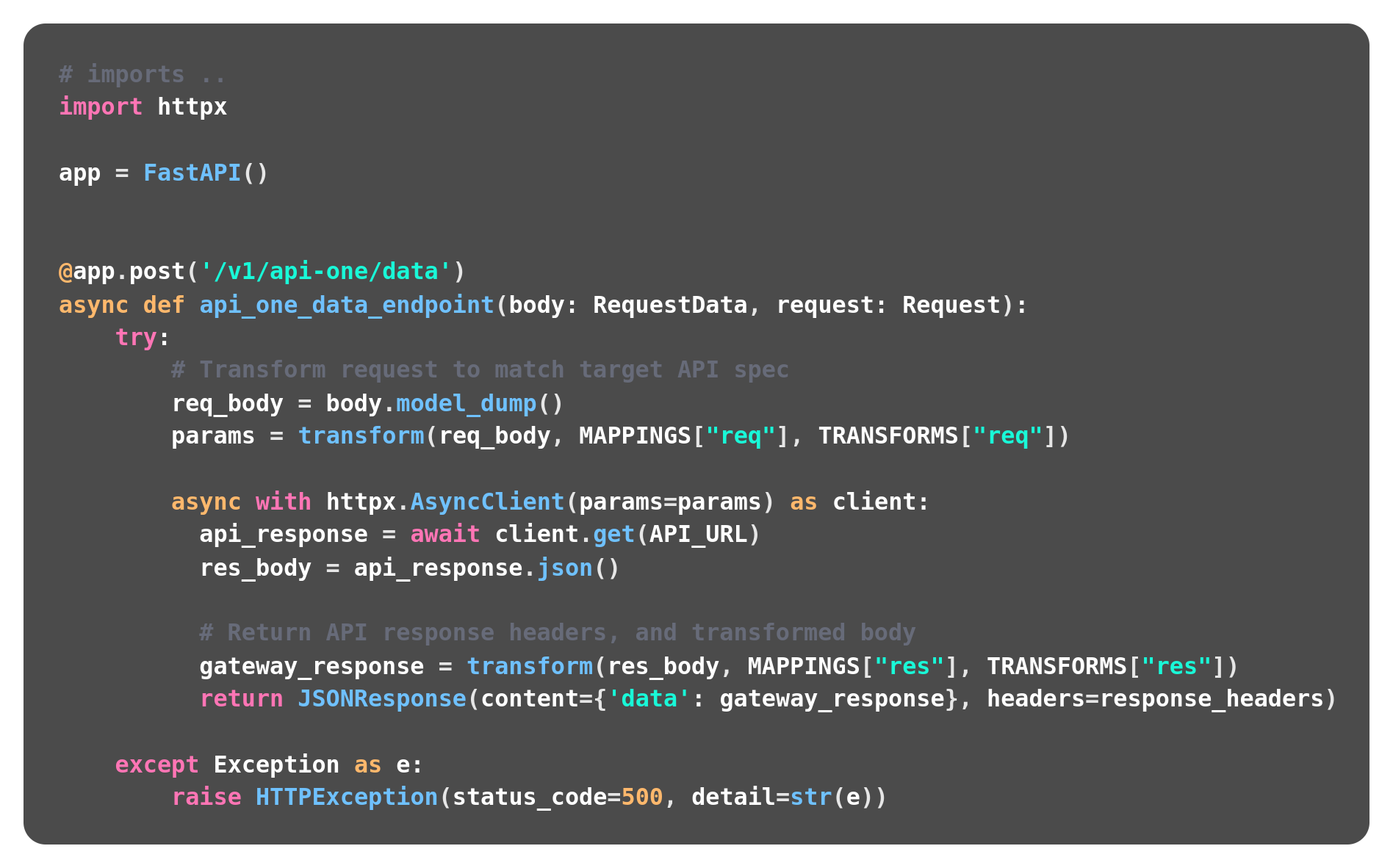
Using asyncio, we can mark functions asynchronous, and await the blocking network I/O call. When the network call is made, await tells uvicorn "Hey go ahead and bring in another request while the OS waits for that outbound request to resolve". Uvicorn then brings in another request to be handled. This massively improved the benchmarks of my FastAPI implementation. The benchmarks were actually very close to web server implementations written in Java, and C#. This made sense to me because our route handlers weren't doing any heavy lifting on the CPU, just transforming the JSON body from POST requests, mapping everything as arguments to a GET request to another internal API, and then doing one more transformation of the JSON response before sending it back to the client.
| Python | Java | NodeJS | C# | |
|---|---|---|---|---|
| Failed Requests | 0 | 0 | 0 | 0 |
| Data Transfer (MB) | 145 | 145 | 145 | 145 |
| Elapsed Time | 15.1 | 16.5 | 19.1 | 16.6 |
| Response Time | 1.3 | 1.4 | 1.7 | 1.5 |
| Txn Rate (Txns/Sec) | 2.6 | 2.4 | 2.1 | 2.4 |
| Throughput (MB/Sec) | 9.5 | 8.9 | 7.6 | 8.7 |
| Concurrency | 3.6 | 3.4 | 3.6 | 3.7 |
| Longest Txn | 3.5 | 4.9 | 5.3 | 5.2 |
| Shortest Txn | 0.12 | 0.2 | 0.3 | 0.1 |
An important aspect to underscore is how concurrency doesn't inherently speed up individual requests, but significantly boosts throughput. In a FastAPI setup, especially when running on a single process without scale-out, concurrency ensures that while a request is waiting in a queue, it's handled more promptly once it reaches the front. This doesn't make the request itself faster but reduces the overall waiting time, creating a perception of increased speed. This principle was evident in our benchmarks, where improved concurrency metrics correlated with better throughput, despite the individual request times remaining fairly consistent.